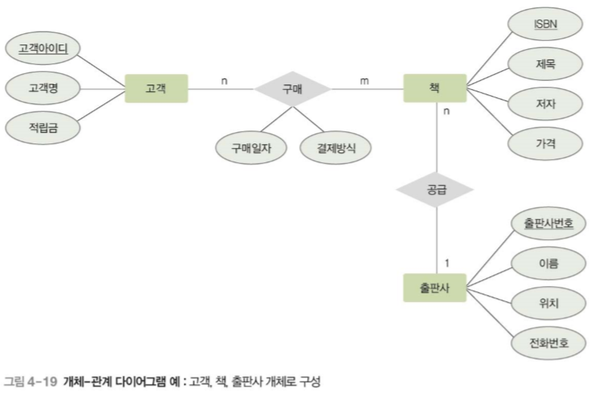
릴레이션 스키마 변환 규칙
E-R 다이어그램에 표현된 개체와 관계는 릴레이션으로 표현하는 방법과 다르다. 그래서 릴레이션 스키마로 변환할 때 규칙을 적용한다.
더 완벽하게 데이터베이스를 설계하기 위해 다섯 가지 규칙을 적용하여 릴레이션 스키마를 설계해보자.
모든 개체는 릴레이션으로 변환한다.
E-R 다이어그램의 각 개체를 하나의 릴레이션으로 변환한다. 개체의 이름을 릴레이션의 이름으로 하고, 개체가 가진 속성도 릴레이션의 속성으로 그대로 변환한다. 이 때 개체가 가지고 있는 속성이 복합 속성(ex 주소 : 우편번호, 기본주소, 상세주소 등으로 여러개의 속성을 가짐 인 경우에는 복합 속성을 구성하고 있는 단순 속성만 릴레이션의 속성으로 변환한다. 개체가 가지고 있는 키 속성은 릴레이션의 기본키로 변환한다.
즉, E-R 다이어그램에 있는 사각형인 개체는 하나의 릴레이션으로, 개체에 연결되어 있는 속성들은 해당 릴레이션의 속성으로 변환한다. 그리고 키 속성을 인수인계한다.
다대다 (n:m) 관계는 릴레이션으로 변환한다.
E-R 다이어그램에 있는 다대다 관계를 하나의 릴레이션으로 변환한다. 관계의 이름을 릴레이션의 이름으로 한다. 즉, 고객과 상품 사이에는 주문이라는 관계가 존재한다. 이는 고객이 여러개의 상품도 주문할 수 있고 여러명의 고객이 하나의 상품을 주문할 수 도 있기 때문에 다대다 관계이다. 이는 관계의 이름을 그대로 가져와 주문 릴레이션으로 변환하고, 주문 관계의 속성들을 그대로 릴레이션의 속성으로 변환한다. 그 후, 관계에 연결된 개체들의 기본키를 가져와 외래키로 지정하고 그 외래키들을 조합해 릴레이션의 기본키로 지정한다.
일대다 (1:n) 관계는 외래키로 변환한다.
E-R 다이어그램에 있는 일대다 관계는 릴레이션으로 변환하지 않고 외래키로만 표현한다. 단, 약한 개체가 참여하는 일대다 관계는 일반 개체가 참여하는 경우와 다르게 처리해야하므로 2개의 세부 규칙으로 나누어서 적용한다.
※ 일반적인 일대다 관계는 외래키로 표현한다.
- 예를 들면 공급이라는 관계에 속해있는 제조업체와 상품이라는 개체가 있다면 다측 즉, 상품 개체에 있는 속성의 외래키로 1측인 공급업체의 기본키인 업체명을 포함한다.
※ 약한 개체가 참여하는 일대다 관계는 외래키를 포함하여 기본키로 지정한다.
- 비행기라는 개체와 좌석이라는 개체가 있을때 비행기가 없으면 좌석이 존재하지 않으므로 좌석은 약한 개체이다. 이 때는 1측에 해당하는 비행기의 기본키인 비행기 번호를 다측인 좌석의 기본키에 외래키로써 포함해야한다. 즉 좌석 릴레이션의 좌석번호, 비행기 릴레이션의 비행기 번호가 좌석릴레이션의 기본키에 포함되어야한다.
일대일 (1:1) 관계는 외래키로 변환한다.
일반적인 일대일 관계는 릴레이션으로 변환하지 않고 외래키로만 표현한다. 예를들어 혼인이라는 관계를 가지는 남자라는 개체와 여자라는 개체가 있다면 배우자의 식별번호가 개체에 외래키로 포함 되어야 한다. 하지만 남자 릴레이션과 여자 릴레이션이 외래키를 모두 가지면 데이터 중복이 발생해서 불필요한 낭비가 생긴다. 이 때는 일대일 관계에 필수적으로 참여하는 개체의 릴레이션만 외래키를 받고, 만약 모든 개체가 일대일 관계에 필수적으로 참여 한다면 릴레이션 하나로 합치는 것이 바람직하다.
다중 값 속성은 릴레이션으로 변환한다.
관계 데이터 모델의 릴레이션에서는 다중 값을 가지는 속성을 허용하지 않는다. 그러므로 E-R 다이어그램에 있는 다중 값 속성으로 별도의 릴레이션을 만들어 포함시키고 그 속성을 가진 개체의 기본키를 외래키로 포함시키고 기본키는 다중 값 속성과 외래키를 조합한다.
기타
다대다 관계만 릴레이션으로 변환했지만 반드시 그럴 필요는 없다. 일대일, 일대다 관계도 릴레이션으로 변환할 수 있다. 특히, 속성이 많은 관계는 유형에 상관없이 릴레이션으로 변환하는 것이 바람직한 경우도 많다. 릴레이션의 개수가 너무 많아져 관리해야하는 DBMS의 부담이 커지지 않게 꼭 필요한 관리를 하는 것이 역량인듯 하다.